
It is interesting that laptops didn't crash as often as desktops in the study. This is especially surprising considering that 1/3 of laptops fail in the first 3 years (article I read about a year ago).
Ron
Microsoft analyzes over a million PC failures, results shatter enthusiast myths
http://www.extremetech.com/gaming/131739-microsoft-analyzes-over-a-million-pc-failures-results-shatter-enthusiast-myths
By Joel Hruska on June 26, 2012 at 4:10 pm
Researchers working at Microsoft have analyzed the crash data sent back to Redmond from over a million PCs. You might think that research data on PC component failure rates would be abundant given how long these devices have been in-market and the sophisticated data analytics applied to the server market — but you’d be wrong. According to the authors, this study is one of the first to focus on consumer systems rather than datacenter deployments.
What they found is fascinating. The full study [1] is well worth a read; we’re going to focus on the high points and central findings. There are two limitations to the data collected that we need to acknowledge. First, the data set we’re about to discuss is limited to hardware failures that actually led to a system crash. Failures that don’t lead to crashes are not cataloged. Second, the data presented here is limited to hardware crashes, with no information on the relative frequency of software to hardware crashes.
CPU overclocking, underclocking, and reliability
When it comes to baseline CPU reliability, the team found that the chance of a CPU crashing within 5 days of Total Accumulated CPU Time (TACT) over an eight month period was relatively low, at 1:330. Machines with a TACT of 30 days over the same 8 months of real-time have a higher failure rate, of 1:190. Once a hardware fault has appeared once, however, its 100x more likely to happen again, with 97% of machines crashing from the same cause within a month.
Overclocking, underclocking, and the machine’s manufacturer all play a significant role in how likely a CPU crash is. Microsoft collected data on the behavior of CPUs built by Vendor A and Vendor B (no, they don’t identify which is which). Here’s the comparison chart, where Pr[1st] is the chance of the first crash, Pr[2nd1] the chance of a second subsequent crash, Pr[3rd2] the chance of a third failure. In this case, overclocking is defined as running the CPU more than 5% above stock.

Are Intel chips just as good as AMD chips? At stock speeds, the answer is yes. Once you start overclocking, however, the two separate. CPU Vendor A’s chips are more than 20x more likely to crash at OC speeds than at stock, compared to CPU Vendor B’s processors, which are still 8x more likely to crash. The report notes that “After a failure occurs, all machines, irrespective of CPU vendor or overclocking, are significantly more likely to crash from additional machine check exceptions.” The team doesn’t break out overclocking failures by percentage above , but their methodology does prevent Turbo Boost/Turbo Mode from skewing results. Does overclocking hurt CPU reliability? Obviously, yes.
So what about underclocking? Turns out, that has a significant impact on CPU failures as well.

As you can see, underclocking the CPU has a significant impact on failure rates. The impact on DRAM might seem puzzling — the researchers only reference CPU speed as a determinant of underclocking, rather than any changes to DRAM clock rate. Our guess is that the sizable impact on DRAM is caused by a slower CPU alone rather than any hand-tuning of RAM clock, RAM latency, or integrated memory controller (IMC) speed. IMC behavior varies depending on CPU manufacturer and product generation in any case, while the size of the study guarantees that a sizable number of Intel Core 2 Duo chips without IMCs would still been part of the sample data.
Laptops vs. desktops, OEM vs. white box
Ask enthusiasts what they think about systems built by Dell, HP, or any other big brand manufacturer, and you aren’t likely to hear much good. Actual data proves that major vendors actually have fewer problems than the systems built by everyone else. The researchers identified the Top 20 computer OEMs as “brand names” and removed overclocked machines from the analysis of the data. Only failure rates within the first 30 days of TACT were considered among machines with at least 30 days of TACT. This is critical because brand name boxes have an average of 9% more TACT than white box systems, which implies that the computers are used longer before being replaced.
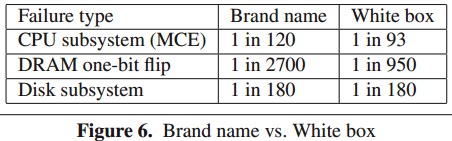
White box systems don’t come off looking very good in these comparisons. CPUs are significantly more likely to fail, as is RAM. Disk reliability remains unchanged.
How about laptops? The researchers admitted that they expected desktops to prove more reliable than laptops due to the rougher handling of mobile devices and the higher temperatures such systems must endure. What they found suggests that laptop hardware is actually more reliable than desktop equipment, despite the greater likelihood that mobile systems will be dropped, sat on, or eaten by a bear. Again, overclocked systems were omitted from the comparison.
Desktops don’t come off looking very good here despite their sedentary nature. The team theorizes that the higher tolerances engineered into the CPU and DRAM, combined with better shock-absorbing capabilities in mobile hard drives may be responsible for the lower failure rate. The difference between SSDs and HDDs was not documented.
More data needed
The limitations of the study are such that we can’t draw absolute conclusions from this data, but they suggest a need for better analysis tools and indicate that adopting certain technologies, like ECC, would help improve desktop reliability. It’s one thing to say that overclocking hurts CPU longevity; something else to see that difference spelled out in data. The impact of underclocking was also quite surprising, this is the first study we’re aware of to demonstrate that running your CPU at a lower speed reduces the chance of a hardware error compared to stock.
The Microsoft team conducted the research as one step towards the goal of building operating systems and machines that are more tolerant of hardware faults. The fact that systems which throw these types of errors are far more likely to continue doing so strikes at the idea that such problems are random occurrences, as does much of the reliability information concerning DRAM.
The report throws doubt on a good deal of “conventional” wisdom and implies reliability is rather sorely lacking. More data is needed to determine why that is, and to correct the problem.
Endnotes
full study: http://research.microsoft.com/apps/pubs/default.aspx?id=144888
: http://www.extremetech.com/wp-content/uploads/2012/06/AMD-vs-Intel.png
: http://www.extremetech.com/wp-content/uploads/2012/06/Underclocking.png
: http://www.extremetech.com/wp-content/uploads/2012/06/Brand-vs-whitebox.png
: http://www.extremetech.com/wp-content/uploads/2012/06/Desktops-vs-Laptops.png
No comments:
Post a Comment